
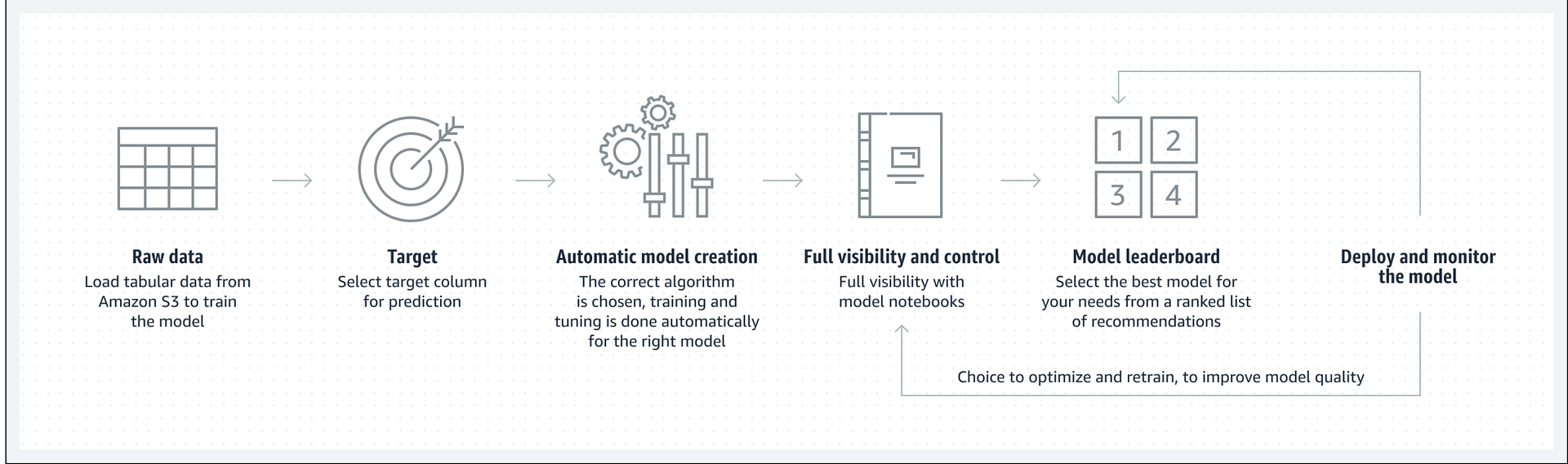
Wartość tej funkcjonalności AWS określa jako “Automatycznie twórz modele uczenia maszynowego z pełną widocznością”. W praktyce oznacza to, że po wskazaniu źródła danych treningowych, Sagemaker w naszym imieniu stworzy kilkanascie wariancji uwzględniejacych inżynierię cech jak, wybór algorytmu jako i samo trenowanie, a następnie stworzy tablice wyników pokazujących efekt (metrykę trenowania) każdego przebiegu.
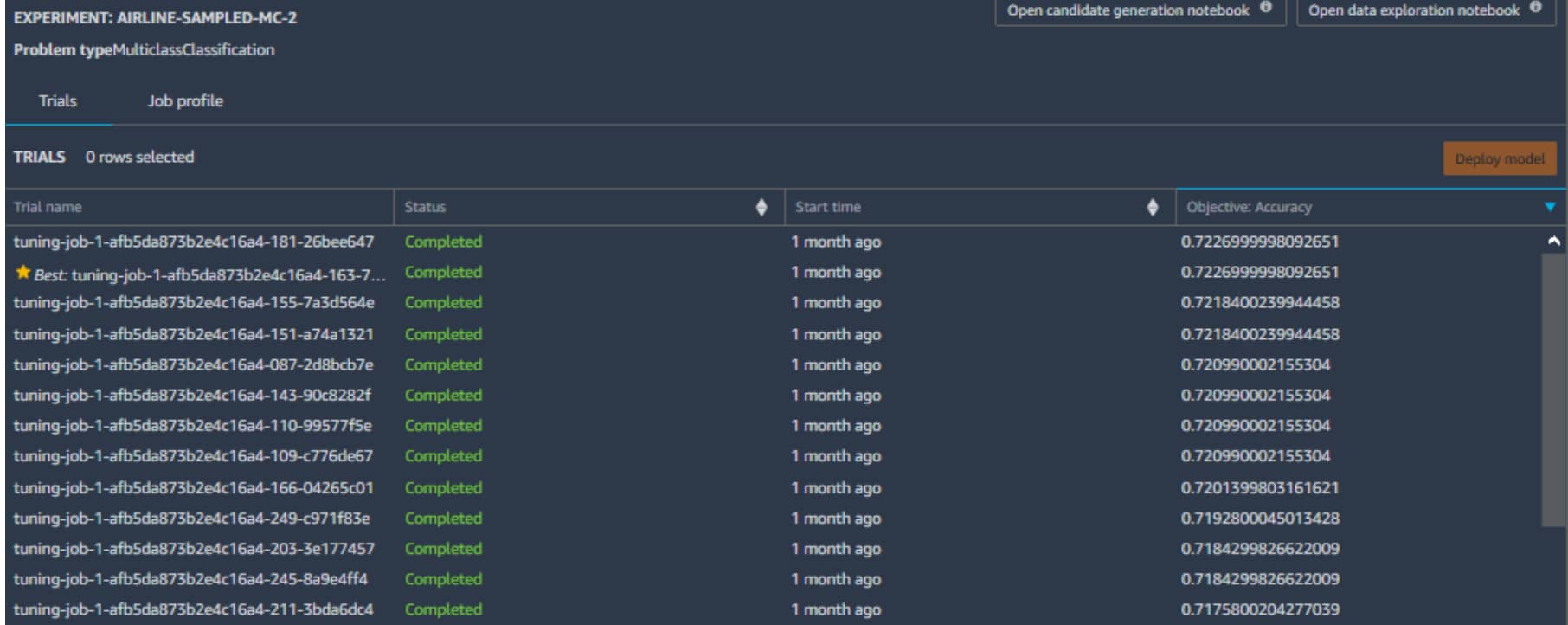
Możemy łatwo wdrożyć wybrany model, co oznacza uruchomienie serwera, za który płacimy za każdą godzinę jego pracy. Następnie możemy wysyłać zapytania sieciowe do tego serwera, aby otrzymywać predykcje na podstawie przekazanych danych. Omówienie procesu wdrożenia wykracza jednak poza zakres tego artykułu.
Korzyści z wygenerowanego Jupyter Notebooka
Największą zaletą jest to, że możemy podejrzeć każdy z eksperyemtnóch w postaci wygenerowanego Jupyter Notebooka. Będzie on zawierał zawiera cały kod, niezbędny do wykonania poszczególnych etapów. Między innymi: instrukcje dotyczące inżynierii cech, zapisywania danych w S3, pobierania odpowiednich uprawnień z IAM, uruchamiania procesu uczenia i prezentacji wyników. Proces uczenia jest realizowany za pomocą interfejsu Estimator, który jest kluczowym elementem usługi Sagemaker.
Wygenerowany Jupyter Notebook jest bardzo pomocny jako punkt wyjścia. Kod, który zostaje wygenerowany, stanowi solidną podstawę i oszczędza czas, który inaczej musielibyśmy poświęcić na zgłębianie dokumentacji dotyczącej przesyłania danych do S3 lub obliczania macierzy pomyłek.
Jest to również szybka metoda oceny danych, która może odpowiedzieć na pytanie: „Czy te dane mają potencjał do przewidywania?”. Oczywiście podstawowym warunkiem jest odpowiednie podzielenie danych na zestawy treningowe i testowe.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły



