
NLP state-of-the-art models demo
Czasy się zmieniły, nie trzeba już być ekspertem od sieci neuronowych, żeby korzystać z głębokich modeli uczenia maszynowego, a przynajmniej się nimi pobawić. A to między innymi dzięki nowemu standardowi wyznaczonemu przez HuggingFaces, które stworzyły wysokopoziomowy, wspólny interfejs dla modeli typu Transformer. Dzięki niemu ten sam sposób pobierzesz, wykorzystasz i dotrenujesz tysiące modeli autorstwa zarówno gigantów z FAANG, jak i pojedynczych kontrybutorów. Jeśli jeszcze nie słyszałeś o HugginFaces, a zajmujesz się przetwarzaniem języka naturalnego albo rozpoznawaniem obrazów, to przeczytaj poprzedni artykuł, który naświetli Ci, dlaczego powinieneś znać to narzędzie.
Wstęp do kodu
Jak zaraz zobaczysz, każdy z przykładów to zaledwie kilka linii kodu, a to za sprawą abstrakcji najwyższego poziomu z biblioteki Transformers – pipeline. Pipeline zawiera w sobie tokenizer i model oraz łączy je ze sobą. W efekcie wystarczy podać rodzaj zadania, a następnie przekazać tekst i voilà – właśnie użyłeś modelu prosto z linii produkcyjnej Google czy Facebooka, które spędzały sen z powiek grupom badawczym.
Wszystkie przykłady, które tu zobaczysz, oraz kilka dodatkowych możesz znaleźć w repozytorium, do którego link znajduje się na końcu wpisu.
Szerokie zastosowanie klasyfikacji tekstu
Klasyfikacja tekstu to technika uczenia maszynowego, która przypisuje zestaw kategorii do dowolnego zlepku słów – od badań medycznych przez fraszki Kochanowskiego do komentarzy na Facebooku. Zapewne wiesz, że każdy komentarz czy to na Youtube, czy na Facebooku przechodzi najpierw przez wiele filtrów określających jego toksyczność, aby w konsekwencji nie dopuścić do jego publikacji. Klasyfikacja tekstu jest wszechobecna w social mediach i właśnie na emocjach oprzemy pierwsze dwa przykłady. Ostatni natomiast pokaże Ci, że model może klasyfikować dowolne kategorie, nawet te, których nie widział w trakcie trenowania.
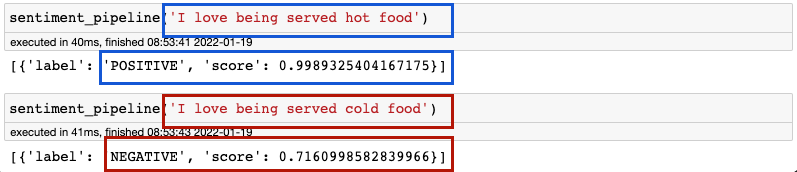
Analiza sentymentu
Ten model przewiduje, czy tekst jest pozytywny czy negatywny, oraz przypisuje rozpoznanej etykiecie wynik – im wyższy, tym większe nasycenie emocjonalne.
Przygotowanie

Demonstracja
Zauważ, jak model znakomicie rozpoznał sarkazm i zaklasyfikował drugi tekst jako ten z negatywnym wydźwiękiem.
Jak rozumieć nazwę modelu distilbert-base-uncased-finetuned-sst-2-english?
- DistilBERT – prefix Distil wskazuje, że użyto metody uogólniania i kompresji wiedzy z pierwszego modelu zwanego nauczycielem (w tym wypadku BERT) do drugiego, zwanego uczniem – modelu docelowego. Zabieg ten pozwolił zmniejszyć rozmiar ostatecznego modelu o 40% oraz przyspieszyć jego działanie o 60% z nieznacznym, bo 3-procentowym ubytkiem zdolności rozumienia tekstu;
- base to rozmiar modelu, czyli liczba parametrów. Zwykle dany model występuje w kilku rozmiarach. Tak samo znajdziesz GPT, GPT-large itp.;
- uncased oznacza, że teksty w trakcie przygotowania zostały sprowadzone do małych liter, a co za tym idzie, dla modelu nie ma znaczenia wielkość liter;
- finetuned–sst2, czyli dotrenowany na zbiorze danych SST-2 (Stanford Sentiment Treebank). Zbiór ten jest jednym ze złotych standardów w ramach analizy sentymentu. Jak każdy bardziej rozpowszechniony zbiór danych ma własny ranking modeli klasyfikujących w nim teksty.
Klasyfikacja emocji
Kolejny model oceni tekst pod względem sześciu emocji. Warto podkreślić, że domyślnie model zwraca wyniki z użyciem funkcji softmax, czyli otrzymamy rozkład prawdopodobieństwa. Oznacza to, że suma zwróconych wartości dla wszystkich emocji sumuje się do 1. Innymi słowy, nawet jałowy tekst, który nie ma potencjału, aby wywołać w Tobie jakiekolwiek uczucia, model przedstawi jako wartości, które po dodaniu dadzą właśnie 1.
Przygotowanie

Demonstracja
Tym razem w formie tabeli. Model wydaje się działać jednostronnie. Dla każdego tekstu wykrywa dominującą emocję i przypisuje jej wynik ponad 99%. Zwróć uwagę, że o ile w pierwszym wierszu model znów dobrze rozpoznał sarkazm, o tyle w trzecim widzimy kardynalną pomyłkę.

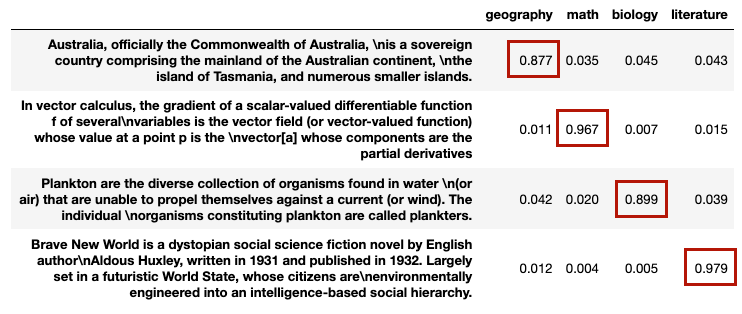
Klasyfikacja dowolnych etykiet metodą zero-shot
Metoda zero-shot pozwala nam klasyfikować dane według wybranych przez nas etykiet, nawet tych, które nie zostały użyte w trakcie trenowania modelu. Ostatnio, szczególnie w NLP, pojęcie to jest używane znacznie szerzej i oznacza skłonienie modelu do zrobienia czegoś, do czego nie został on wyraźnie wytrenowany. Pokazuje to, że ekstremalnie duże modele językowe mogą osiągać konkurencyjne wyniki w zadaniach niższego rzędu (jak klasyfikacja czy rozpoznawanie encji) przy znacznie mniejszej ilości danych dla tego konkretnego zadania, niż wymagałyby tego mniejsze modele przeznaczone do pracy nad danym problemem.
Przygotowanie

Demonstracja
Zobacz, jak bezbłędnie model przyporządkował fragmenty do szkolnych przedmiotów.
Podsumowanie
Przykłady klasyfikacji tekstu można mnożyć. Wykrywanie zdań zawierających satyrę czy plagiat również można zaliczyć do tej kategorii zadań NLP. Więcej przykładów możesz znaleźć na stronie paperswithcode.com, żeby szerzej poznać spektrum możliwości.
Jeśli interesują Cię również inne zastosowania przetwarzania języka naturalnego, to podobny wpis znajdziesz tutaj.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły


