
Artykuł w serii
Model danych wpływa nie tylko na charakter zarządzania danymi na przestrzeni dyskowej, ale i na to, jak myślimy o problemie, a co za tym idzie – na rozwój aplikacji. Nie oznacza to, że go determinuje, a raczej ogranicza nasze pole manewru, zarówno mentalne, jak i implementacyjne. Innymi słowy, wybranie modelu danych wpływa na przyszłe możliwości i ograniczenia.
Jest wiele różnic pomiędzy bazami SQL i NoSQL, jak obsługa równoległości czy spójności danych, tutaj jednak skupimy się wyłącznie na modelu danych.
Bazy klucz–wartość
Klucz–wartość to najprostszy z modeli. Bazy te przypominają swoją charakterystyką słownik czy hash dostępny chyba w każdym języku programowania (jeśli znasz język programowania, który nie ma tej struktury, daj mi znać). Najbardziej popularny przedstawiciel tego gatunku to Redis, którego rozwinięcie brzmi Remote Dictionary Server – nazwa mówi sama za siebie. Wartości nie mają predefiniowanego schematu, może nią być cokolwiek. Inni przedstawiciele to KeyDB oraz DynamoDB.
Bazy Dokumentowe
Bazy dokumentowe w porównaniu do baz klucz–wartość wprowadzają pewien porządek dotyczący wartości. Ich struktura dalej może być niejednorodna pomiędzy wpisami, ale ma wyglądać jak słownik / hash. Jest ona zwana dokumentem. Dokument to, z założenia, złożona struktura. Pozwala wykonywać zapytania na podstawie pól w dokumentach oraz wyciągać i zapisywać fragmenty dokumentu. W bazach klucz–wartość nie jest to możliwe właśnie ze względu na nieprzejrzysty format wartości.
W bazach dokumentowych cała wartość jest przechowywana w jednym kawałku. Więc jeśli chcemy wyciągnąć cały dokument, to mamy przewagę względem bazy relacyjnej, która musi pozbierać informacje najczęściej z wielu tabel, oczywiście jeśli normalizujemy bazę, co jest złotym standardem, o czym pisałem wyżej.
Innymi słowy, potrzebne jest mniej odczytów z dysku w bazach dokumentowych do pobrania tych samych informacji w obrębie jednego dokumentu. Baza relacyjna będzie pobierać informacje z wielu tabel, które są rozrzucone w przestrzeni dyskowej. Dopóki duże albo całe fragmenty dokumentu są wyciągane częściej niż jego pojedyncze pola, dopóty to podejście jest lepsze.
Ma to również swoje wady. Tak długo, jak będziemy chcieli nadpisać cały dokument, lokalność danych będzie korzystna, jednak do nadpisania jednego pola w dokumencie i tak cały zostanie na nowo wstawiony do bazy (wyjątkiem jest sytuacja, kiedy chcemy nadpisać nową wartość i jej binarna reprezentacja mieści się w przestrzeni, którą zajmuje stara wartość)
Elastyczny schemat modelu dokumentowego
Wraz z wejściem na scenę baz dokumentowych ukuto termin schemaless, które jest mylące. Przecież kod aplikacyjny oczekuje pewnej struktury i typów, kiedy pobiera dane. Dlatego dużo lepszym określeniem jest określenie schema-on-read lub implicit schema.
Przeciwieństwem tego pojęcia jest oczywiście schema-on-write, tak powszechna w bazach relacyjnych.
Analogią dla schema-on-read i schema-on-write jest dynamiczny i kompilacyjny type-checking.
Porównanie baz relacyjnych i dokumentowych
Bazy dokumentowe i relacyjne mimo różnic w modelu danych w podobny sposób tworzą relacje (jeden do wielu i wielu do wielu), przechowują bowiem unikalny identyfikator jako odnośnik do innego wpisu. W bazach relacyjnych nazywany jest on kluczem obcym (foreign key), a w bazach dokumentowych – document reference. Warto podkreślić, że nie wszystkie bazy dokumentowe wspierają joiny. Nawet jeśli API klienta na to pozwala, pod spodem może to być emulowane zachowanie w warstwie klienta, w przeciwieństwie do relacyjnych silników, gdzie optymalizator odpowiada za łączenie danych.
Schema-on-read jako jeden z głównych wykładników baz dokumentowych również ma swoje odzwierciedlenie w bazach relacyjnych poprzez wprowadzenie typu kolumny, która przechowuje zagnieżdżone, elastyczne struktury jak JSONb. Ten typ kolumny jest traktowany jako dokument, a więc schema-on-read.
Przedstawiciele dokumentowego modelu danych to: MongoDB, CouchDB, Elasticsearch.
Wspólny mianownik baz klucz–wartość oraz dokumentowych
Linia oddzielająca model klucz–wartość i dokumentowy wygląda bardziej jak kreska w akwareli niż ostrze PolSilvera. Rozwiązania klucz–wartość pozwalają na przechowywanie dodatkowych metadanych dla wartości. Na ich podstawie budujemy indeksy, co przypomina bazy dokumentowe.
W bazach dokumentowych główny indeks pochodzi z identyfikatora dokumentu. Czy nie przypomina to przypadkiem klucza głównego w bazach klucz–wartość? Te dwa aspekty nie są jednak tak istotne jak ostatni.
W obu tych modelach jednostką rozliczeniową jest wartość. Całą wartość wyciągamy, całą wartość nadpisujemy. Martin Fowler zamyka oba te modele danych w pudełku o nazwie aggregate-oriented. Nazwa jest oczywiście zaczerpnięta z „Domain Driven Design” Erica Evansa. Kluczowa charakterystyka domenowego modelowania problemu zawiera się w haśle: „rzeczy, które zmieniają się razem, trzymamy razem”. Przykładowo w relacyjnej bazie encja „zamówienie” będzie rozrzucona po wielu tabelach. W bazach zorientowanych na agregat będzie to jedna wartość nie tylko po stronie aplikacyjnej, ale i po stronie persystencji.
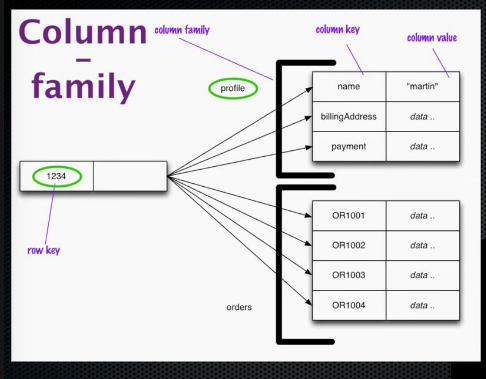
Bazy rodziny kolumn (Column family)
Bazy NoSQL rodziny kolumn zawierają wiersze i kolumny. Każdy wiersz jest jednoznacznie identyfikowany przez klucz. Każdy wiersz ma wiele kolumn, z których każda ma nazwę, wartość i sygnaturę czasową. W przeciwieństwie do tabeli w relacyjnych bazach wiersze w tej samej rodzinie kolumn / tabeli nie muszą dzielić tego samego zestawu kolumn, a kolumna może być dodana do jednego lub wielu wierszy w dowolnym momencie.
Analogicznie do relacyjnych baz danych rodzina kolumn jest czymś w rodzaju „widoku” wielu tabel. Może być również postrzegana jako mapa tabel.
Dojrzałym przedstawicielem tego gatunku jest Apache Cassandra oraz BigTable autorstwa Google. Dalszą charakterystykę przeanalizujemy na podstawie Cassandry.

Doprecyzujmy jeszcze raz model danych. Każdy klucz w Cassandrze odpowiada wartości będącej obiektem. Każdy klucz ma wartości w postaci kolumny, a kolumny są pogrupowane w zestawy zwane rodzinami kolumn. W ten sposób każdy klucz identyfikuje rząd o zmiennej liczbie elementów (kolumn). Te rodziny kolumn można by wówczas uznać za tabele.
Rozproszenie danych w Apache Cassandra
Apache Cassandra wspiera nawet replikację pomiędzy centrami danymi. Dodatkowo każdy węzeł w klastrze ma tę samą rolę. Oznacza to, że nie ma jednego punktu awarii (single point of failure), a każdy węzeł może obsłużyć każde żądanie.
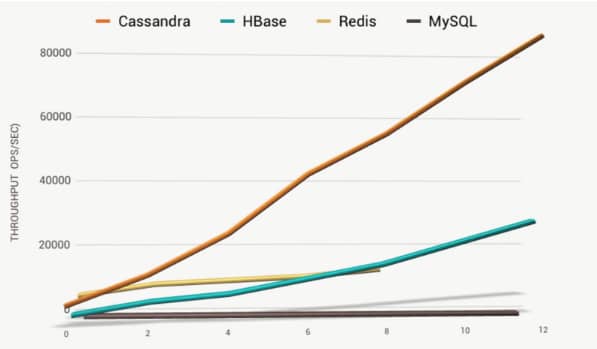
Bardzo istotną cechą systemów rozproszonych jest to, jak się skalują, kiedy dokładamy kolejne węzły obliczeniowe. Cassandra jest zaprojektowana tak, aby przepustowość odczytu i zapisu zwiększała się liniowo wraz z dodawaniem nowych maszyn.
A co z joinami? Cassandra nie wspiera joinów, a kładzie raczej nacisk na denormalizację. Dzieje się tak, ponieważ obciążenie pojedynczego wyszukiwania klucza jest stosunkowo duże (usługa musi ustalić, który węzeł [węzły] ma wykonać zapytanie, a jednocześnie wysyłać zapytania i czekać na odpowiedzi). Przez narzut rozumiem opóźnienie, a nie ograniczenie przepustowości.
Jako callout
Column-family databases to nie to samo co bazy zorientowane na kolumny (column-oriented). Te drugie to często bazy relacyjne przeznaczone do analityki (data warehouse, na przykład Amazon Redshift). Są to bazy relacyjne, natomiast przechowują dane tabel na dysku według kolumn zamiast według wierszy.
Bazy grafowe
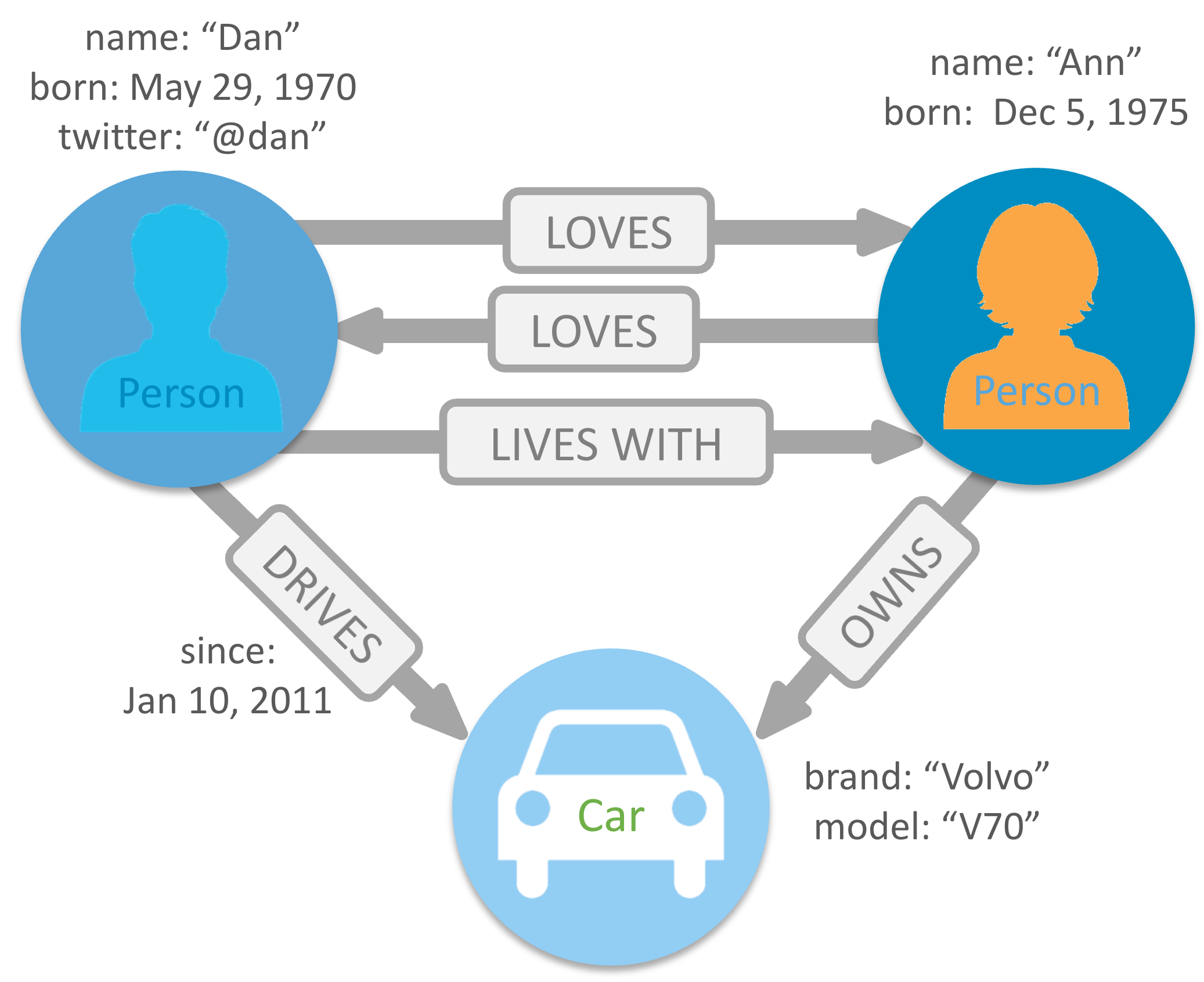
Doskonałym przykładem grafu są dane serwisu społecznościowego. Wyobraź sobie, że wierzchołki to poszczególni użytkownicy, komentarze, wydarzenia. Każdy wierzchołek ma swoje atrybuty. Dla użytkownika będzie to wiek, a dla komentarza – data utworzenia. Krawędzie to rodzaj relacji pomiędzy wierzchołkami, krawędź pomiędzy użytkownikiem a komentarzem będzie oznaczała, kto go napisał, krawędź pomiędzy użytkownikami może oznaczać, kto kogo zna lub kto kogo dodał do czarnej listy. Jeśli temat grafów jest dla Ciebie obcy albo po prostu potrzebujesz wprowadzenia, znajdziesz je tutaj.

{kind=link}
Bazy grafowe są właśnie stworzone do tworzenia relacji wszystkiego ze wszystkim. Graf nie musi być jednorodny dla jednej encji, jak to pokazuje powyższy przykład.
Oczywiście można to zamodelować poprzez kilka tabel w bazie relacyjnej, jednak trawersowanie pomiędzy wierzchołkami nie należy do wygodnych ani optymalnych zadań. Co więcej, część zapytań, które są błahostką w bazach grafowych, w bazach relacyjnych wymaga użycia egzotycznych rekursywnych common table expressions.
W tym miejscu kończymy część porównania baz NoSQL ze względu na model danych. Jak widzisz, NoSQL to bardzo szeroki termin.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły



4 thoughts on “Podział baz NoSQL ze względu na model danych: klucz-wartość, dokumentowe, rodzina kolumn, grafowe [SQL vs NoSQL 4/6]”
Comments are closed.