
Czyli jak korzystać z modeli state-of-the-art za pomocą jednego interfejsu
Dynamika rozwoju NLP
Przetwarzanie języka naturalnego (NLP) to obszar głębokiego uczenia maszynowego, który nabrał niezwykłego pędu po tym, jak w 2017 r. na scenę wdarł się Transformer. Architektura ta pozwala bowiem uczyć modele z nieetykietowanych danych z większą efektywnością niż poprzednie rozwiązania. Pewnie kojarzysz modele takie jak BERT czy GPT, odbiły się przecież głośnym echem nawet w niespecjalistycznych artykułach — oba bazują właśnie na architekturze transformer, a dokładnie chodzi o zawarty w nim mechanizm uwagi.
Gwoli wyjaśnienia, czym jest uczenie z nieetykietowanych danych tekstowych — polega ono na uzupełnianiu tekstu. W uproszczeniu:
- Oryginalne zdanie: „Przeszedłem na drugą stronę ulicy”.
- Dane treningowe: „Przeszedłem na drugą [MASK] ulicy”.
- Zadaniem modelu jest przewidywanie, jakie słowo kryje się pod tokenem [MASK].
O zbiory tekstów w dobie internetu nietrudno. Tysiące książek, miliony wpisów na blogach takich jak ten czy potoki komentarzy w social mediach są pożywką dla coraz większych modeli. Od przybytku głowa nie boli. Im ich więcej, tym większy potencjał na lepszy model. Jak wspominałem w jednym z ostatnich artykułów, model będzie tak dobry jak dane, którymi go karmiliśmy, a głównym wyznacznikiem potencjału danych jest ich rozmiar.
Dodatkowo cała ta przyspieszająca lokomotywa NLP jest napędzana przez udostępnianie kolejnych rozwiązań w ramach wolnego oprogramowania – nie tylko w formie prac badawczych opisujących, jak zbudować i wytrenować model, ale i gotowych modeli, czyli milionów, a nawet miliardów wag.
Grupy badawcze wymyślają coraz lepsze rozwiązania, a nam, reszcie aktorów z uniwersum ML, przychodzi znaleźć dla nich zastosowania i ewentualnie udoskonalić model.
Na tym właśnie polega idea współczesnego NLP, aby wykorzystać wcześniej wytrenowany model ogólnego użytku, który ma dobre rozumienie słowa pisanego, a następnie dotrenować pod konkretne zadanie.
Zasadniczym problemem dość długo było to, że każdy model – czy to T5, czy RoBERTa – miał inny interfejs ładowania, dotrenowania i wnioskowania. Weźmy na przykład oficjalne repozytorium na swój czas przełomowego modelu T5, pochodzącego z google-research. Jak go użyć?
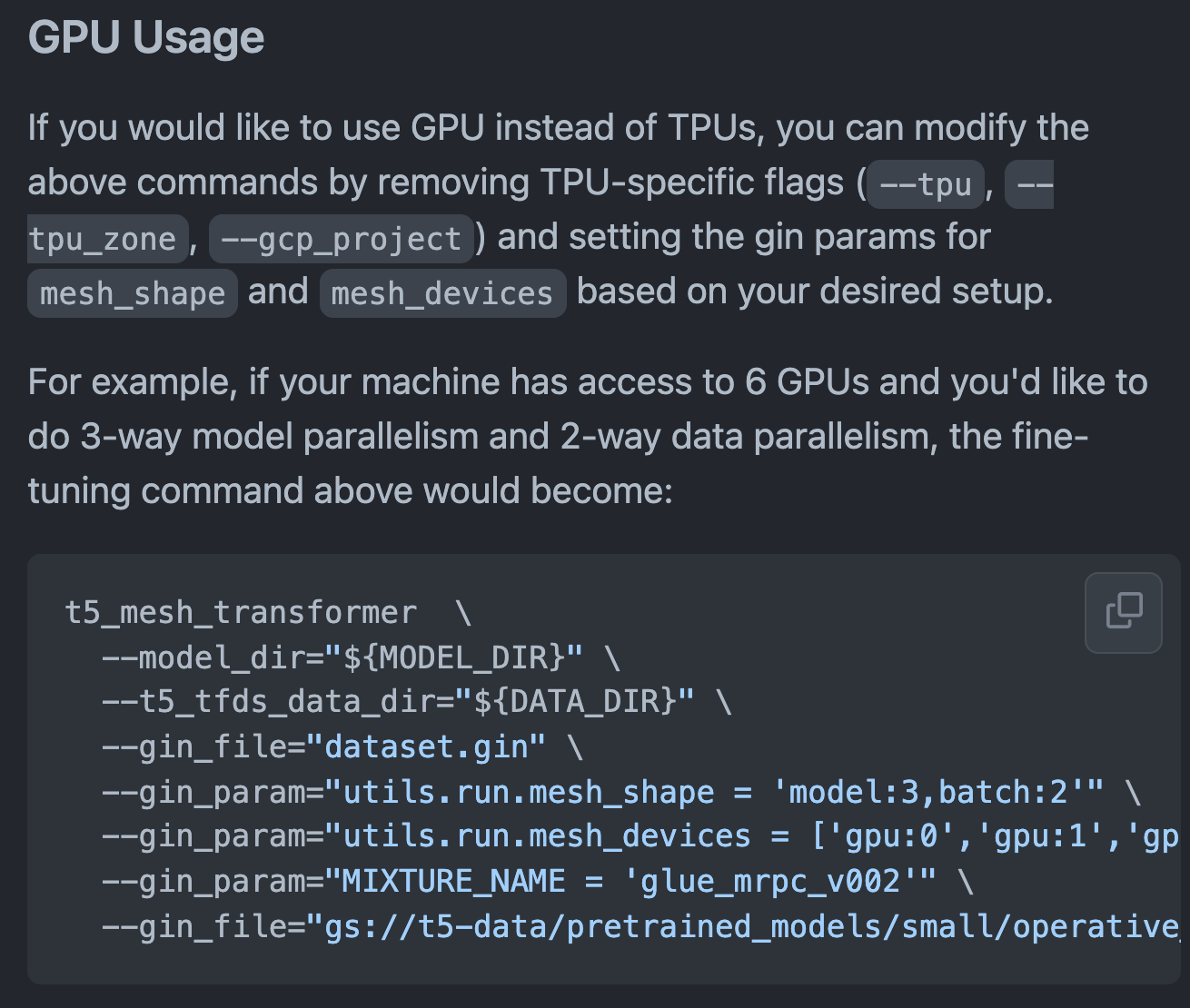
A co jeśli chcę porównać go z innym modelem? Znów szukam niestandardowego kawałka kodu. A co jeśli chcę pracować, korzystając z PyTorcha? Wiadomo, Google wypuściło swój model oparty na Tensorflow. Czyli szukam narzędzia, które skonwertuje wagi z jednego frameworku do drugiego.
I wtedy właśnie wchodzi HuggingFaces, całe na biało.
Jeden interfejs, by rządzić wszystkimi
Z HuggingFaces wystarczą dwie linie kodu, żeby korzystać z modeli, które były trenowane przez gigantów z FAANG przez setki godzin. Tak, modele z miliardami parametrów są dostępne na wyciągnięcie ręki.
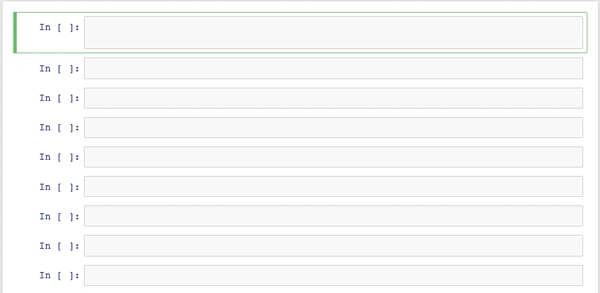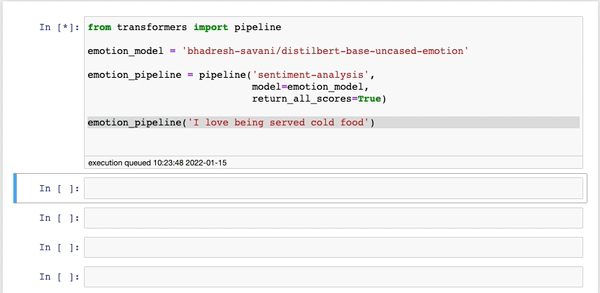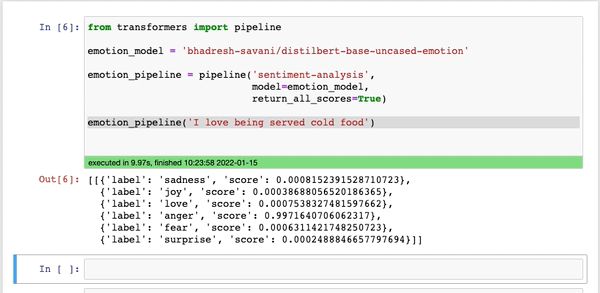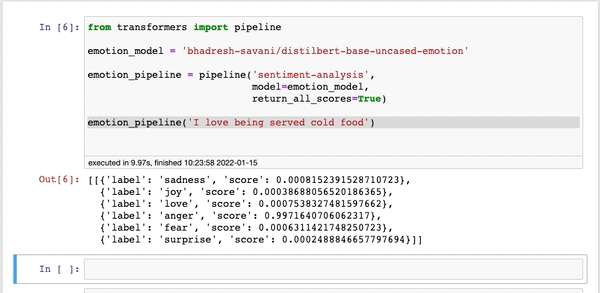
Jeśli potrzebujesz modelu, który określa emocje z tekstu czy wygeneruje nagłówek dla artykułu, to problem jest podobny jak po otwarciu Netflixa – nie wiadomo, na który model się zdecydować.
Według taksonomii zadań NLP HuggingFaces oferuje modele zgrupowane w 13 kategoriach i ponad 170 językach.
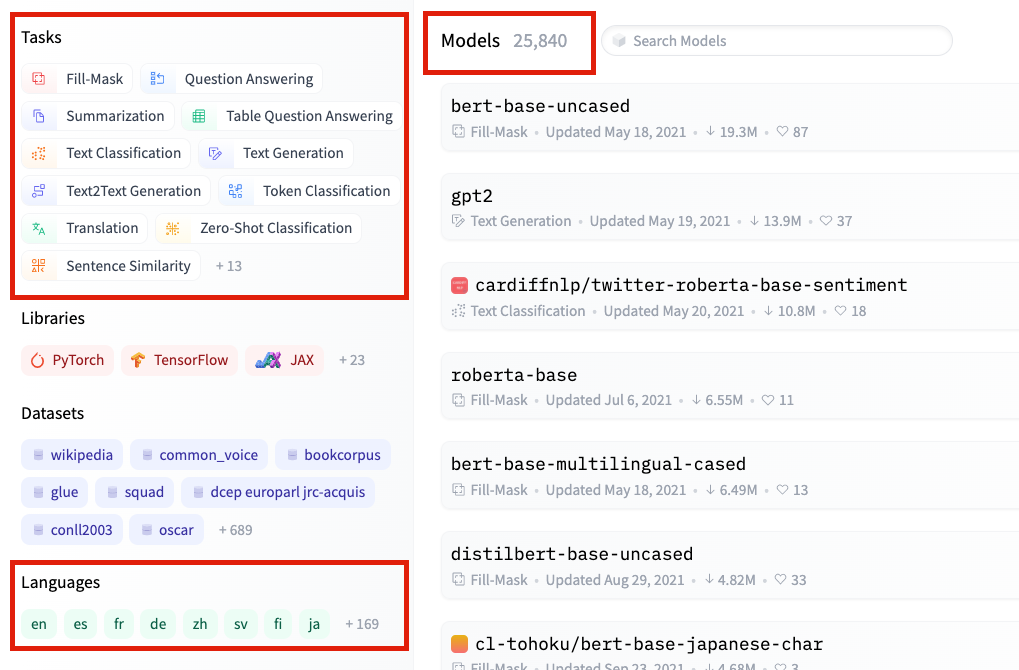
Autorytet HuggingFaces
Odpowiedzialny programista przed dodaniem zależności do kodu czy oparciem systemu na zewnętrznym serwisie sprawdzi wiarygodność źródła. Spokojnie, wykonałem tę pracę za Ciebie.
Firma tworząca bibliotekę Transformers w momencie pisania tego tekstu jest po 5 rundach finansowania i pozyskała od inwestorów 60,2 milionów dolarów, z czego ostatnia z marca 2021 r. opiewa na 40 milionów dolarów. Prawdą jest, że wytwarzanie oprogramowania spala więcej niż 5-litrowe V8 na setkę, co nie zmienia faktu, że dzięki temu finansowaniu Transformers stali się monopolistami na rynku. Omawiane repozytorium zdobyło aż 55 tysięcy gwiazdek na githubie
Na głównej stronie znajdujemy również informacje o organizacjach korzystających z HuggingFaces, których nie trzeba przedstawiać.

Co więcej, AWS w swojej usłudze do SageMaker stworzył integrację pozwalającą trenować i hostować modele pochodzące z katalogu HuggingFaces

Nie tylko NLP
Nazwa Transformers odnosi się do architektury sieci neuronowych, a ta jest wynoszona na piedestał również w computer-vision i audio. HuggingFaces konsekwentnie dodaje modele w kolejnych dziedzinach deep learningu.
Czy HuggingFaces to rozwiązanie Twojego problemu?
To zależy. Może się okazać, że bardziej dostosowanym rozwiązaniem będzie korzystanie z AI jako usługi niż zajmowanie się utrzymywaniem własnych modeli.
Najbardziej powszechne zadania, jak analiza sentymentu, rozpoznawanie encji czy identyfikacja języka, są dostępne jako API u świętej trójcy dostawców chmury internetowej.
Wystarczy jedno zapytanie sieciowe do AWS, Azure czy GCP, żeby zrealizować te i wiele innych zadań związanych z NLP czy CV, bez utrzymywania modeli, bez obciążania własnej infrastruktury. Oczywiście nawet najbardziej trywialne operacje przy pewnej skali taniej jest robić u siebie.
Natomiast jeśli faktycznie zajmujesz się budowaniem i trenowaniem modeli w dziedzinach NLP czy CV, to przynajmniej powinieneś spróbować HuggingFace. Tak wynika z moich doświadczeń z ostatniego projektu, w którym stanąłem przed zadaniem przewidywania wskaźników marketingowych, mając do dyspozycji samą treść wiadomości. Innymi słowy, musiałem prognozować, który tekst jest bardziej klikalny. Nadal jestem zdumiony, jak łatwo wykorzystać i żonglować modelami SOTA.
Podsumowanie
NLP wręcz się domagało ustandaryzowania pobierania i korzystania z modeli. Lukę tę bezkonkurencyjnie wypełniło HuggingFaces biblioteką Transformers. Czy pojawią się alternatywy w przyszłości? Rozsądek mówi, że tak, ale to dobrze, bo rywalizacja w kapitalistycznym świecie służy wszystkim, płodząc lepsze rozwiązania. Na razie, zważywszy również na powagę organizacji, nie ma co się zastanawiać, tylko przynajmniej spróbować tego rozwiązania w następnym projekcie. U mnie się sprawdziło i wciąż sprawdza, mam nadzieję, że Tobie też.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły


