
NLP state-of-the-art models demo
Czasy się zmieniły, nie trzeba już być ekspertem od sieci neuronowych, żeby korzystać z głębokich modeli uczenia maszynowego, a przynajmniej się nimi pobawić. A to między innymi dzięki nowemu standardowi wyznaczonemu przez HuggingFaces, które stworzyły wysokopoziomowy, wspólny interfejs dla modeli typu Transformer. Dzięki niemu ten sam sposób pobierzesz, wykorzystasz i dotrenujesz tysiące modeli autorstwa zarówno gigantów z FAANG, jak i pojedynczych kontrybutorów. Jeśli jeszcze nie słyszałeś o HugginFaces, a zajmujesz się przetwarzaniem języka naturalnego albo rozpoznawaniem obrazów, to przeczytaj poprzedni artykuł, który naświetli Ci, dlaczego powinieneś znać to narzędzie.
Taksonomia zadań NLP
To nieoczywisty temat. Nie ma jednej instytucji, która ma monopol na kategoryzowanie zadań NLP. Problem polega na tym, że jedno zadanie przeplata się z drugim. Na przykład prowadzenie konwersacji należy do osobnej kategorii conversational, a przecież mogłoby być podkategorią generowania tekstu. Dodatkowo kategoryzowanie zadań NLP rozmija się z systematyką modeli, ponieważ jeden model może realizować kilka różnych zadań. Innymi słowy, klasyfikacja zadań i modeli to dwie osobne taksonomie, oczywiście mające ze sobą wiele wspólnego, jednak próby ich łączenia są daremne. Z tego powodu w poniższych przykładach znajdziesz zarówno opis i przykłady samych zadań, jak i kilka słów o modelach, których użyjemy do demonstracji.
Wstęp do kodu
Jak zaraz zobaczysz, każdy z przykładów to zaledwie kilka linii kodu, a to za sprawą abstrakcji najwyższego poziomu z biblioteki Transformers – pipeline. Pipeline zawiera w sobie tokenizer i model oraz łączy je ze sobą. W efekcie wystarczy podać rodzaj zadania, a następnie przekazać tekst i voilà – właśnie użyłeś modelu prosto z linii produkcyjnej Google czy Facebooka, które spędzały sen z powiek grupom badawczym.
Wszystkie przykłady, które tu zobaczysz, oraz kilka dodatkowych możesz znaleźć w repozytorium, do którego link znajduje się na końcu wpisu.
Generowanie kontynuacji tekstu
To, jakie zadanie może realizować model, wynika z tego, jak był trenowany. Zatem do generowania kontynuacji tekstu świetnie się sprawdzi model, który za zadanie miał przewidywać kolejne słowo na podstawie wyrazów go poprzedzających. Dla przykładu:
- Zdanie wejściowe:
It has never been so good. - Dane treningowe:
It has never been so [mask] - Słowo, które model ma przewidzieć:
good
Ten charakter trenowania modelu pozwala generować płynnie brzmiący tekst. Technika ta nosi nazwę causal language modeling – CLM (łatwo o literówkę, bo to nie casual tylko causal – ja żyłem w tym błędzie wystarczająco długo, aby mieć teraz nową misję życiową i chronić innych przed tym faux pas). Największymi celebrytami grona CLM są oczywiście członkowie rodziny GPT i też jednego z nich użyjemy do pierwszego przykładu. Zobacz, jak działa w praktyce model, który swego czasu był wynoszony na piedestał.
Przygotowanie
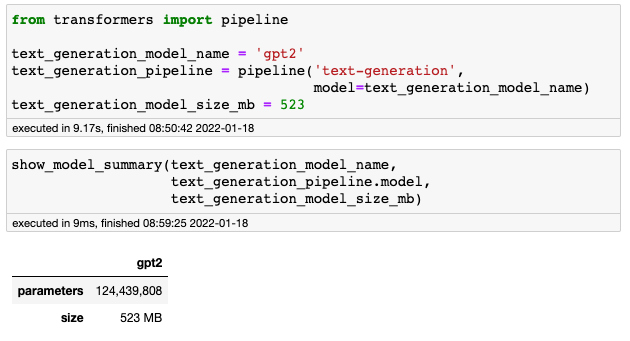
Tak, wystarczą dwie linie kodu, żeby załadować model o rozmiarze 124 milionów parametrów. Gdybyś chciał dokonać eksperymentów na jeszcze większych modelach to repozytorium Transformers oferuje GPT-J o rozmiarze 6 miliardów parametrów, czyli bestię prawie 50 razy większą od GPT-2.
Demonstracja
Wystarczy podać maksymalną długość oczekiwanej sekwencji oraz liczbę propozycji dokończenia tekstu, które chcemy zobaczyć, a do generowania różnorodnych rezultatów przy kolejnych wywołaniach ustawiany ziarno (seed).
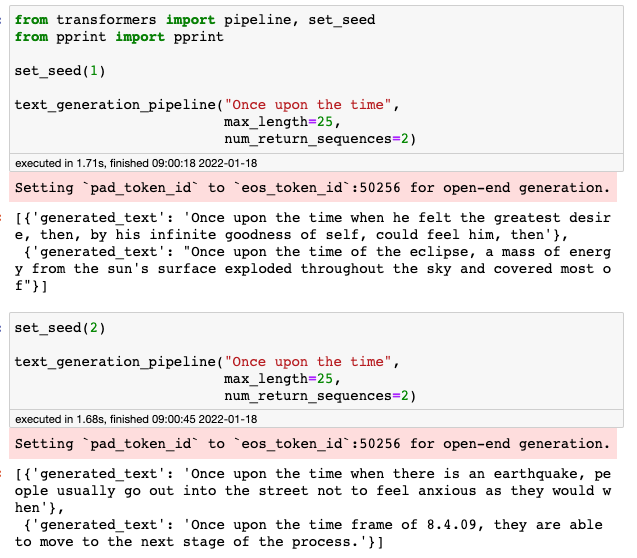
Ograniczenie do 25 nie sprawi, że model domknie frazę, po prostu jest to liczba słów, które wygeneruje.
Odpowiadanie na pytania
Czy możemy spodziewać się, że model, od którego oczekujemy odpowiedzi, kryje w sobie encyklopedie? Otóż nie. Jeśli chcesz odpowiedzi na pytanie, musisz również podać fragment, w którym znajduje się odpowiedź – zwany również kontekstem. Czyli jeśli ciekawi Cię, ile ludzi żyje w Australii, Twoim obowiązkiem jest podać notkę geograficzną o tej części świata.
Przygotowanie
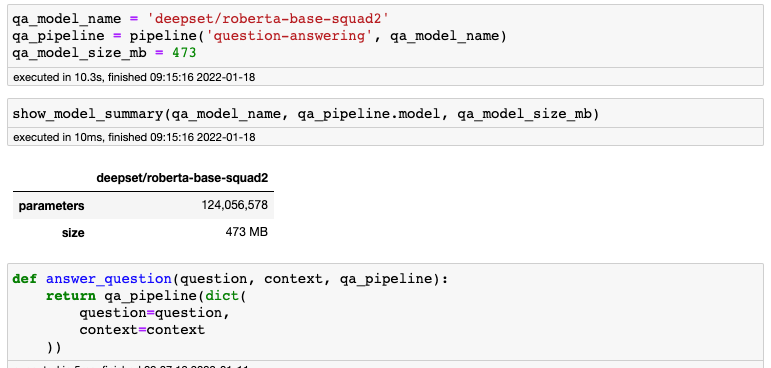
Demonstracja
Żeby zaspokoić Twoją ciekawość dotyczącą populacji najmniejszego kontynentu, zadajmy to pytanie Robercie. Kontekst – notka wycięta z Wikipedii – zawiera słowo population. Żeby podnieść nieco poprzeczkę, zadamy trzy sparafrazowane pytania.
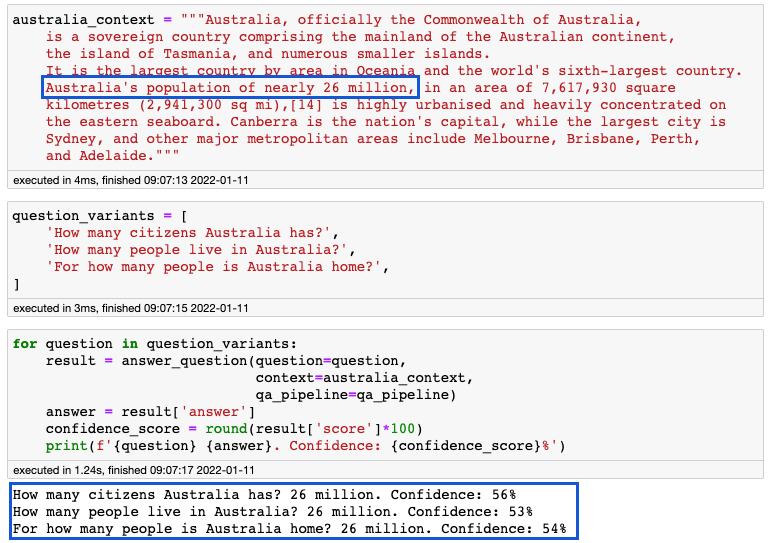
Miłe zaskoczenie czy oczekiwany rezultat? Istotne jest to, że model wykazał się rozumieniem tekstu. Mimo wszystko to pytanie było łatwe, ponieważ kontekst był krótki. Gdybyśmy podali dłuższy tekst, opisujący zmiany demograficzne tego państwa z ostatnich trzech dekad, model nie sprostałby oczekiwaniom. Im więcej podobnych do siebie informacji, tym trudniej o prawidłową odpowiedź.
Odpowiedź, której udziela model, to fragment tekstu. Mamy dokładnie zaznaczone, gdzie się ona zaczyna, a gdzie kończy.
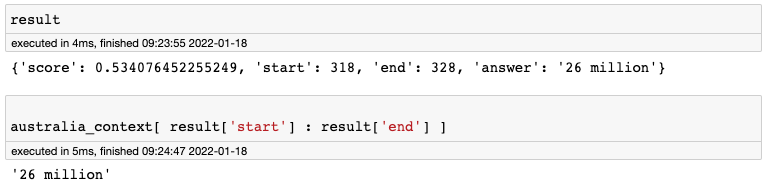
Jak rozumieć nazwę modelu deepset/roberta-base-squad2?
- deepset to organizacja, która udostępniła model w repozytorium HuggingFace;
- roberta, a dokładnie RoBERTa, to model zbudowany na podstawie modelu BERT. Na czym polegała modyfikacja? Po pierwsze zmieniono sposób przygotowania maskowania zbioru treningowego na bardziej efektywny, użyto o rząd większego zbioru danych i trenowano dłużej. Dzięki tym kilku zabiegom RoBERTa tworzy lepsze reprezentacje, a zadania pochodne (downstream tasks) dają lepsze rezultaty;
- base to rozmiar modelu, czyli liczba parametrów. Zwykle dany model występuje w kilku rozmiarach. Tak samo znajdziesz GPT, GPT-large itp.
Do tej pory omówiliśmy sam model, który został użyty jako fundament, aby następnie stworzyć na nim (dotrenować) nowy. Stąd ostatni człon nazwy.
- squad2 to nazwa zbioru danych – Stanford Question Answering Dataset (SQuAD) – składającym się z pytań zadawanych przez osoby w odniesieniu do zbioru artykułów Wikipedii, gdzie odpowiedzią na każde pytanie jest fragment tekstu. Wyjaśnia to zachowanie modelu, prawda? Oznacza to, że metapytania, na przykład o liczbę zdań tekstu, nie mają sensu.
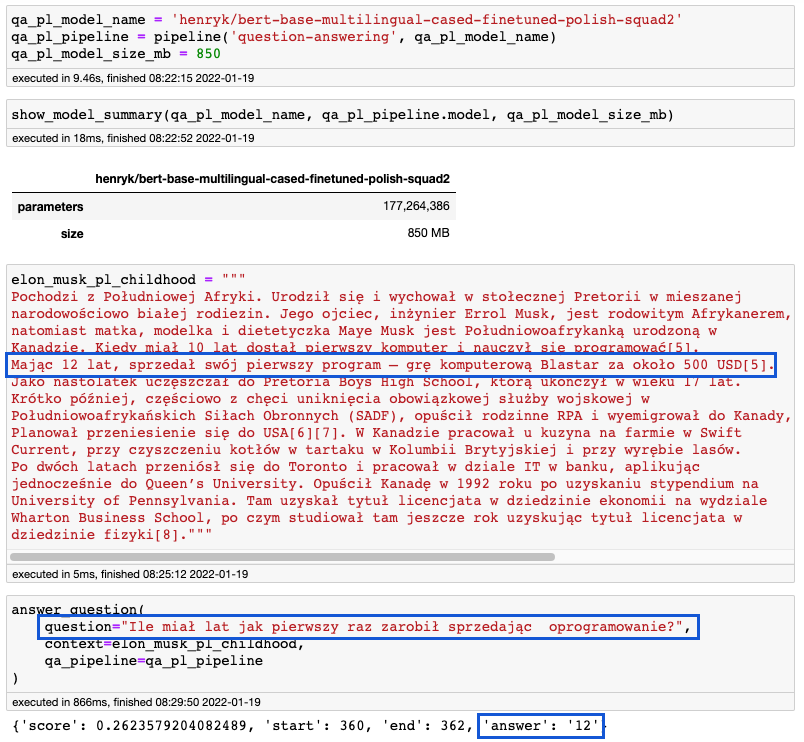
Demonstracja w języku polskim
Tak, modele odpowiadają na pytania również w naszym rodzimym języku. Ten powstał z dotrenowania wielojęzycznej wersji BERTa dostarczonej przez Google na tym samym, tyle że wcześniej przetłumaczonym, zbiorze danych co opisany wyżej – SQuAD2. Zresztą teraz, widząc nazwę modelu (pierwsza linia kodu poniżej), sam o tym dobrze wiesz.
Generowanie podsumowań
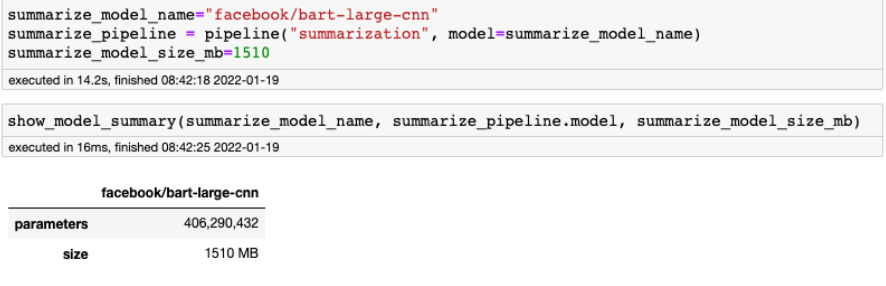
Tym razem model od Facebooka. Jego podstawą jest BART-large, a został dotrenowany na zbiorze CNN Daily Mail o wielkości zaledwie 300 tysięcy unikalnych artykułów. Format zbioru danych idealnie wpisuje się, aby stworzyć model generujący syntezę tekstu.
Bowiem każdy element zbioru danych ma dwa pola:

Przygotowanie
Demonstracja

Model wyciągnął esencję tekstu poprzez wybranie najistotniejszych fragmentów. Kolejny raz widzimy, że modele wpadają w pułapkę urwania zdania w połowie. Wynika to z nałożenia przez nas ograniczenia maksymalnej długości generowanego podsumowania.
Podsumowanie
W tym krótkim przeglądzie użyliśmy modeli, których nie sposób wytrenować w domowym zaciszu. Wystarczy kilka linii kodu, żeby eksplorować potencjał nawet tych stworzonych przez największe organizacje technologiczne. Jak widzisz, charakter trenowania wyznacza ich możliwości i ograniczenia. Jeśli wcześniej nie korzystałeś z biblioteki Transformers, to mam nadzieję, że jesteś miło zaskoczony, z jaką łatwością można korzystać z gotowych modeli głębokiego uczenia maszynowego. Choć ich działanie przedstawione w demonstracjach pozostawia jeszcze wiele do życzenia, to trzeba przyznać, że wykazały niezłą dozą – sztucznej, bo sztucznej, ale jednak – inteligencji.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły



One thought on “NLP poniżej 10 linii kodu. Generowanie kontynuacji tekstu, podsumowań oraz odpowiedzi na pytania”
Comments are closed.