Ocena modeli klasyfikacyjnych jest trudniejsza niż regresyjnych. W większości przypadków jedna metryka jak MSE czy MAE jest wystarczająca, aby oddać jakość modelu regresyjnego. Natomiast ewaluacja modeli klasyfikacyjnych wymaga zrozumienia kilku metryk, by przedstawić pełny obraz jakości modelu, adresując również niezbalansowane zbiory danych. Aby czuć się w tym temacie swobodnie należy, zrozumieć czym jest tablica pomyłek oraz bazujące na niej metryki takie jak: precision, recall, specificity i F1. Dodatkowo terminologia i synonimy tworzą dodatkową barierę.
Ten artykuł ma na celu przybliżyć właśnie te zagadnienia w intuicyjny sposób. Na łamach kolejnych akapitów będę wymiennie używał angielskich i polskich określeń. W codziennym użytku zapewne wystarczy znać wyłącznie angielską formę, jednak uważam że przynajmniej warto się obyć z polskim nazewnictem. Mam nadzieje że nie utrudni to odbioru.
Fundament – tablica pomyłek
Rozważmy następujący scenariusz: chcemy ocenić działanie modelu, który przewiduje czy na zdjęciu jest kot, czy go nie ma. 1 oznacza, że model zidentyfikował kota na zdjęciu a 0, że go nie ma.

Na pierwszy rzut oka są dwie możliwości albo model dobrze ocenił, albo źle. Jednak tak naprawdę istnieją 4 warianty.
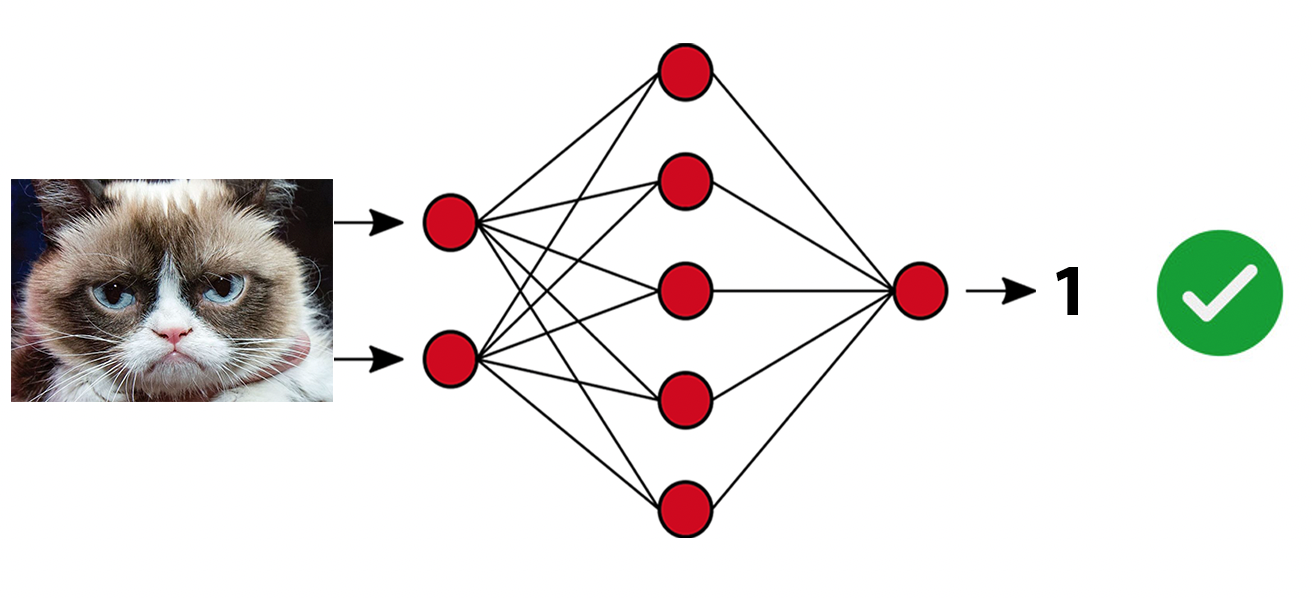
Możliwość 1 – karmimy model zdjęciem kota i model przewiduje 1 – prawidłowa predykcja.
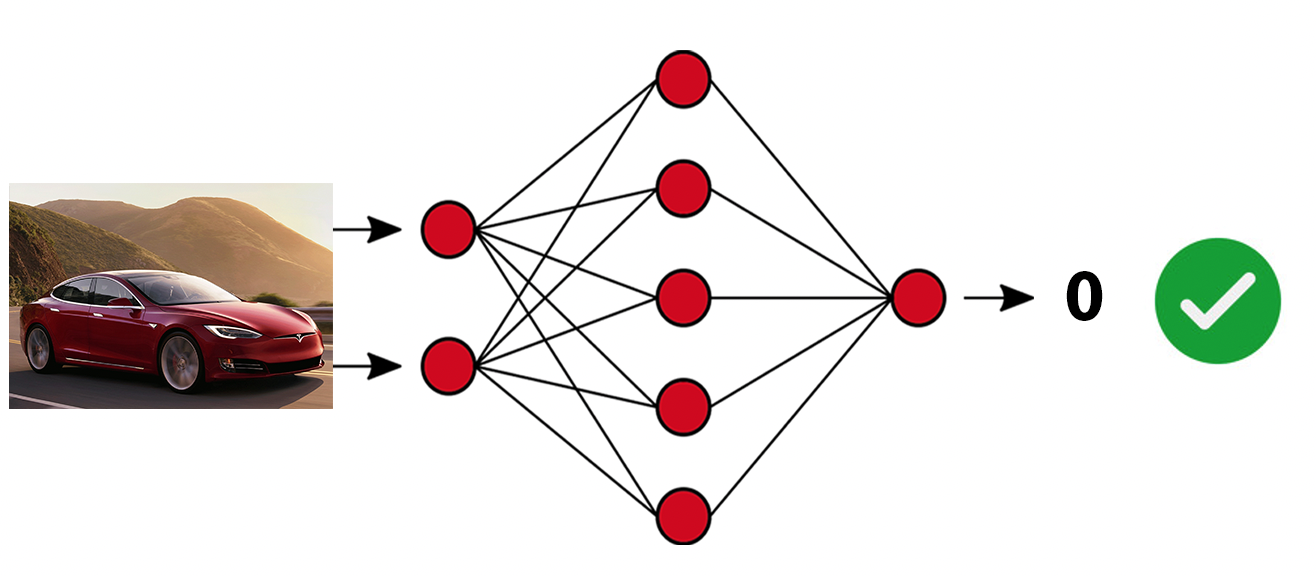
Możliwość 2 – karmimy model zdjęciem bez kota i model przewiduje 0 – prawidłowa predykcja.
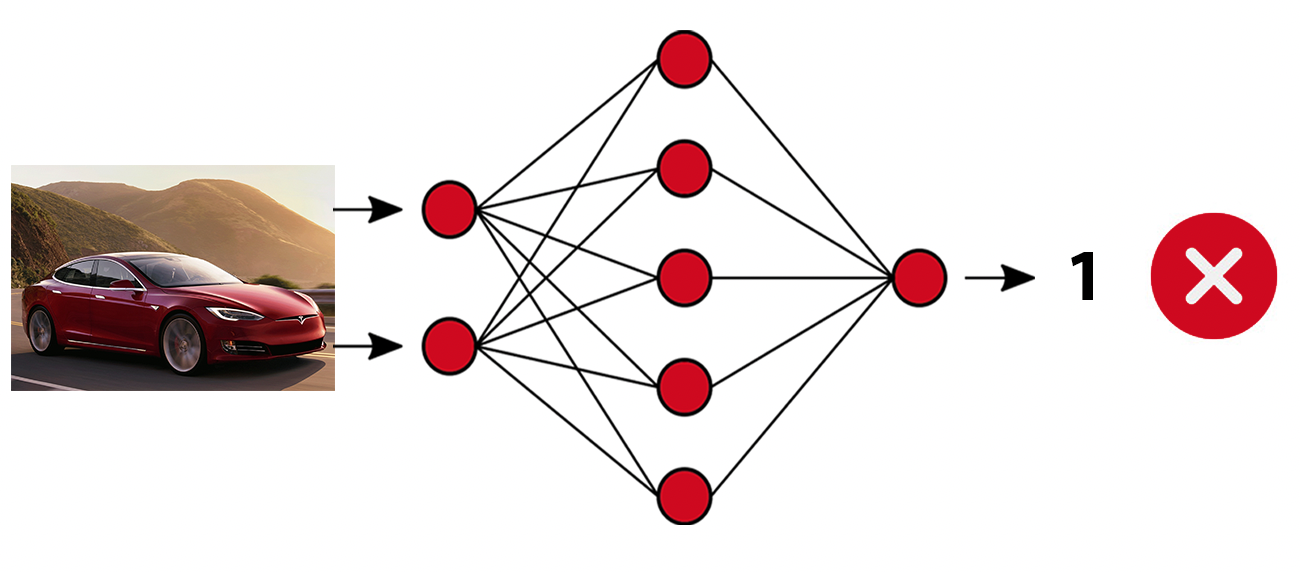
Możliwość 3 – karmimy model zdjęciem kota, a model przewiduje 0 – nieprawidłowa predykcja.

Możliwość 4 – karmimy model zdjęciem bez kota, a model przewiduje 1 – nieprawidłowa predykcja.
Skondensowana forma w postaci tabeli wygląda następująco:

Wprowadźmy teraz powszechnie stosowane oznaczenia:

Ta forma zapisu predykcji modelu w zestawieniu z prawdziwymi etykietami nosi nazwę tablicy pomyłek i stanowi fundament pod szereg metryk, które w zwartej formie przedstawiają jej jakość.
Rozmiar tablicy pomyłek jest definiowany przez liczbę klas, które przewidujemy. Warto zauważyć, że tylko na przekątnej znajdują się prawidłowe predykcje.

Uogólniona tablica pomyłek (confusion matrix) w angielskiej formie dla dwóch klas przyjmuje taką oto postać:

Rozwinięcie skrótów:
- TP – true positive
- TN – true negative
- FP – false positive
- FN – false negative
Dlaczego jednak warto się rozwodzić nad 4 wariantami?
Ponieważ jest znacząca różnica pomiędzy fałszywie negatywny i fałszywie pozytywny.
Aby oddać tę różnicę, przeanalizujemy konsekwencje obu błędów w kilku przypadkach.
Fałszywie pozytywny funkcjonuje również pod nazwą fałszywy alarm oraz błąd pierwszego rodzaju. To na przykład, osoby zdrowe są zaklasyfikowane jako chore.
Fałszywie negatywny również posiada dwie inne nazwy: błąd drugiego rodzaju oraz niedoszacowanie. To na przykład zdjęcie z guzem mózgu, które zostało zaklasyfikowane jako zdrowy.
Aby oddać ciężar gatunkowy różnicy pomiędzy tymi błędami, osadźmy je w komercyjnym przykładzie.
Konsekwencje pierwszego i drugiego rodzaju w ocenie ryzyka kredytowego
Wytrenowaliśmy dwa modele, które przewidują ryzyko kredytowe. Wyniki modelu służą wsparciu procesu decyzyjnego, gdzie przewidujemy czy należy przyznać pożyczkę, czy też nie. Etykiety zbioru danych to:
- 0 – osoba będzie miała problem ze spłatą
- 1 – brak problemu ze spłatą.
Który z tych modeli będzie lepszym kandydatem? To zależy.

Kiedy model się pomyli występują dwa scenariusze, jak zawsze dla klasyfikacji binarnej:
- Nie udzielimy kredytu osobie, która nie miałaby problemu ze spłatą. Konsekwencją jest utratą zysków z udzielonej pożyczki.
- Udzielimy kredyt osobie, która będzie miała problem ze spłatą. Konsekwencją są dodatkowe koszty banku w postaci np. windykacji środków czy postępowania sądowego.
Których przypadków zatem chcemy mieć mniej? A może stosunek kosztu obu błędów wynosi 2:1 i chcemy to uwzględnić podczas wyboru najlepszego modelu?
Kiedy już poznamy odpowiedź na te pytania, chcemy wybrać najlepszy model, który zmaksymalizuje zyski przedsiębiorstwa. Porównywanie macierzy pomyłek jest jednak mało wygodne. Istnieją bowiem metryki bazujące na niej i wyrażają w jednej wartości to co dla nas istotne. Taki sposób porównywania modeli, za pomocą jednej wartości, znacznie upraszcza ewaluację.
Zanim jednak do metryk…
Nieporozumienia i utrudnienia
Problem z macierzą pomyłek wynika z braku spójnego przyporządkowania wierszy i kolumn. Na samej Wikipedii na pierwszy rzut oka widzimy jej dwa warianty, gdzie zamieniono wiersze z kolumnami.

Angielski żart słowny dobrze opisuje tę sytuację, “confusion matrix is confusing”.
Wszystkie 4 warianty dla klasyfikacji binarnej wyglądają następująco.

Jedynym sposobem jest zatem zrozumieć, a nie zapamiętać.
Podstawowe metryki
Czułość / Recall
Odpowiada na pytanie: ile procent ze wszystkich zdjęć, na których jest kot, model dobrze zaklasyfikował.
Recall = \frac{TP}{TP + FN}Jeśli wszystkie zdjęcia z kotami zostaną dobrze rozpoznane, czułość = 100%.
To metryka z perspektywy etykiet zbioru treningowego, w tym wypadku z perspektywy zdjęć, na których jest kot.

Uogólniając, to stosunek prawdziwie dodatnich, do wszystkich próbek o etykiecie dodatniej. Wszystkie próbki o etykiecie dodatniej (wszystkie zdjęcia z kotem) składają się natomiast z pozytywnie dodatnich i negatywnie ujemnych.
- Im wyższa czułość, tym niższy błąd drugiego rodzaju.
- Im wyższa czułość, tym lepiej
Interpretacja
Czułość interpretuje się jako zdolność modelu do rozpoznania klasy tam, gdzie ona występuje.
Kiedy to jest ważne?
W sytuacji kiedy nierozpoznanie klasy tam, gdzie ona występuje, ma większe konsekwencje niż fałszywy alarm, czyli rozpoznanie klasy tam, gdzie jej nie było.
Przykład dla klasyfikacji dla 3 klas
Recall jest wyliczane dla każdej z klas osobna.

Inne nazwy
- TPR – true positive rate
- Sensitivity – dla klasyfikacji binarnej
Swoistość / Specificity
Specificity = \frac{TN}{TN + FP}Odpowiada na pytanie: ile procent ze wszystkich zdjęć, na których kota nie ma, model dobrze zaklasyfikował.
Jeśli wszystkie zdjęcia, na których kota nie ma, zostaną dobrze rozpoznane swoistość = 100%.
To metryka z perspektywy etykiet zbioru treningowego, w tym wypadku z perspektywy zdjęć gdzie kota nie było.
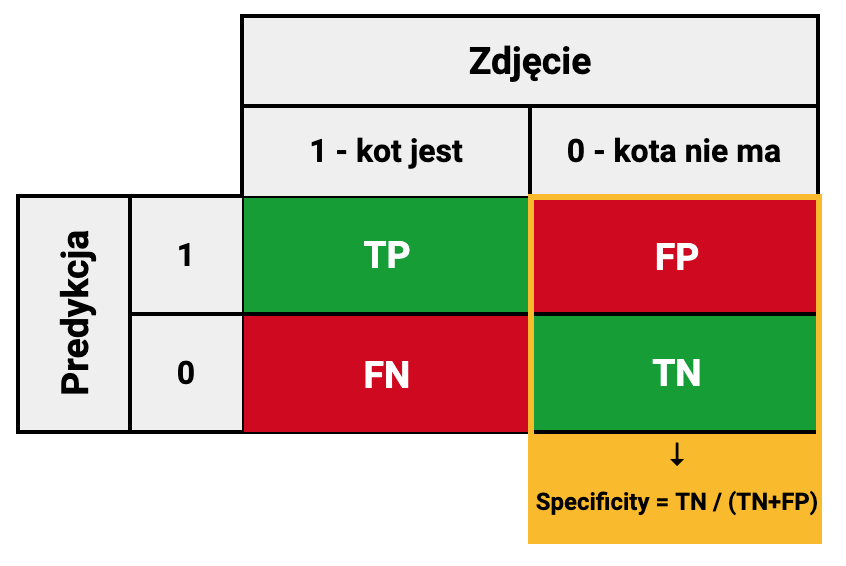
Uogólniając, to stosunek prawdziwie negatywnych, do wszystkich próbek o etykiecie negatywnej. Wszystkie próbki o etykiecie negatywnej (wszystkie zdjęcia bez kota) składają się natomiast z pozytywnie negatywnych i fałszywie pozytywnych.
- Im wyższa swoistość, tym niższy błąd pierwszego rodzaju, czyli tym mniej fałszywych alarmów
- Im wyższa swoistość, tym lepiej
Interpretacja
Ogólnie rzecz biorąc, swoistość interpretuje się jako zdolność modelu do poprawnego odrzucenia klasy tam, gdzie ona nie występuje.
Przykład dla klasyfikacji dla 3 klas
Specificity jest wyliczane dla każdej z klas osobna.
Pies_true_negatitves – zdjęcia na których psa nie było i model dobrze je zaklasyfikował.
Pies_false_positives – zdjęcia na których pies nie było, ale model twierdzi, że jest.

Inne nazwy:
- TNR – True negative rate
- Selectivity
Precyzja / Precision
Precision = \frac{TP}{TP + FP}Odpowiada na pytanie ile zdjęć, na których model zidentyfikował kota, faktycznie na nich kot był.
Jeśli wszystkie zdjęcia, które model zaklasyfikował jako kot, zostały dobrze ocenione precyzja = 100%.
To metryka z perspektywy predykcji.
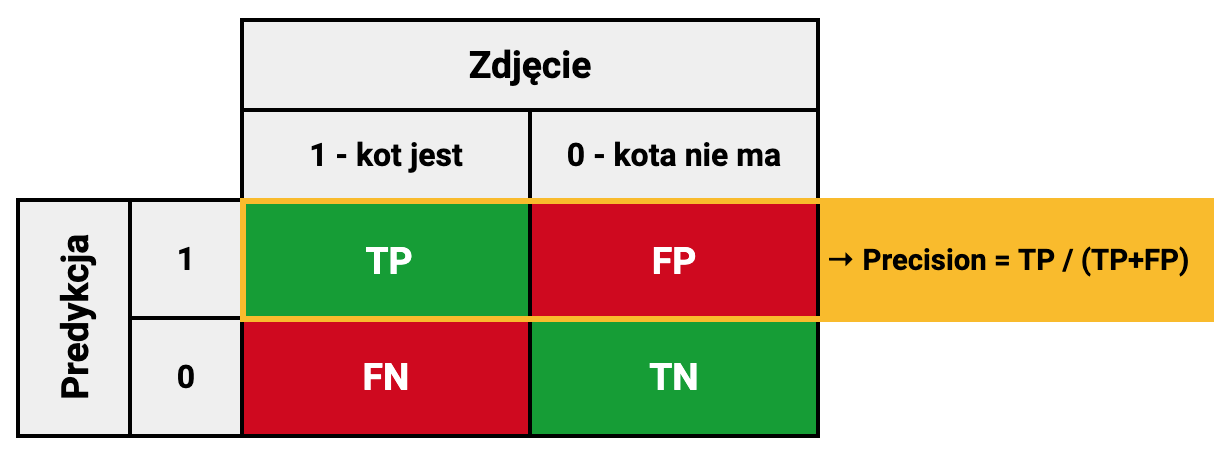
Uogólniając, to stosunek prawdziwie dodatnich, do wszystkich próbek którym model nadał klasę dodatnią. Wszystkie próbki, którym model nadał klasę dodatnią, składają się z prawdziwie dodatnich i fałszywie dodatnich.
Im wyższa precyzja, tym niższy błąd pierwszego rodzaju, tym mniej fałszywych alarmów.
Przykład dla klasyfikacji dla 3 klas
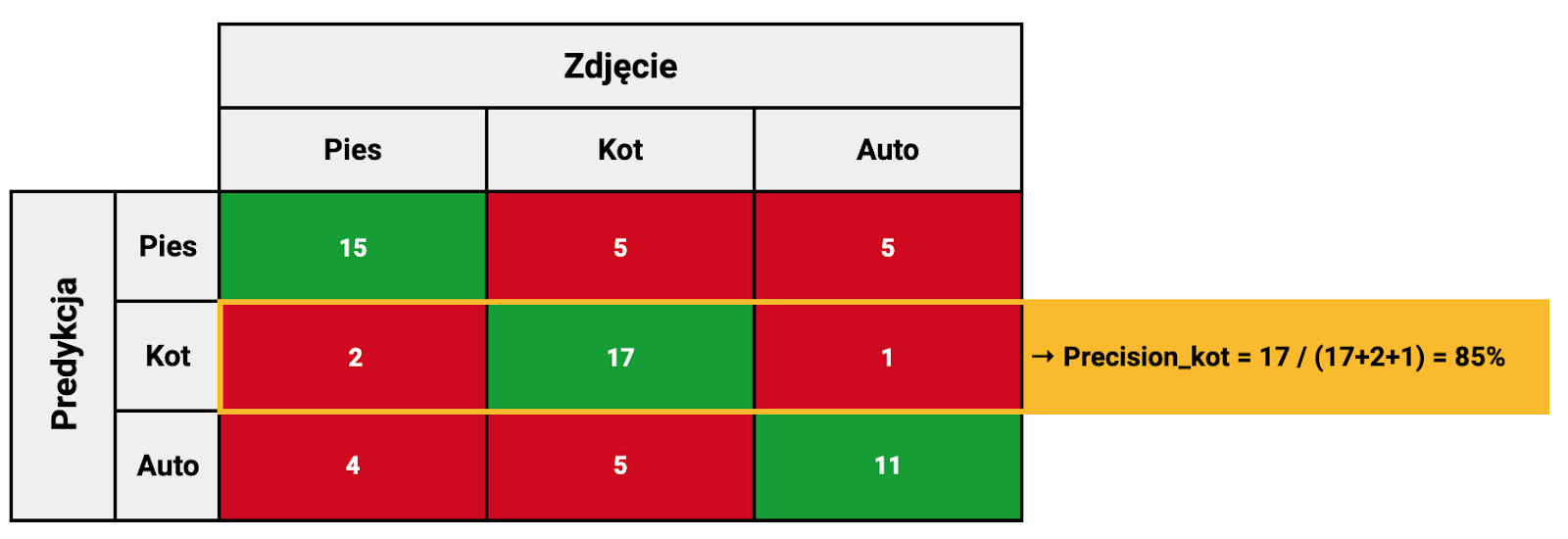
Podsumowanie metryk bazujących na 2 komórkach tablicy pomyłek oraz interakcje między nimi
Zmiana progu klasyfikacji
Większość modeli klasyfikacyjnych zwraca prawdopodobieństwo danej klasy, a nie wartość 0 czy 1. Punktem wyjściowym jest ustalenie progu predykcji na wartość 0,5. To znaczy, że predykcjach o wartościach < 0.5 klasyfikuje się jako 0 a predykcje >= 0,5 jako 1.
Przesuń suwakiem progu klasyfikacji, aby zaobserwować jak zmieniają się metryki kiedy zmienia się próg klasyfikacji.
Zarówno czułość, swoistość jak i precyzja są ważnymi wskaźnikami dokładności testu, jednak osobno nie dają pełnego obrazu. Tylko wspólnie dają one pojęcie o stopniu zaufania, jakim można darzyć dany model.
Można nawet powiedzieć, że nie ma sensu rozważać wyżej opisanych metryk w oderwaniu od siebie, ponieważ wystarczy zmienić próg klasyfikacji i wszystkie metryki ulegają zmianie Na przykład poprawiając Recall spadnie Specificity i vice versa.
Powszechnie wybiera się takie pary jak Recall i Specificity oraz Recall i Precision, ponieważ obie te pary uwzględniają wszystkie możliwe pomyłki, jakie model może popełnić.
F1 – średnia harmoniczna precission i recall
Spróbujmy przestawić jakości modelu łącząc Precision i Recall za pomocą kolejnej metryki bazującej na ich podstawie. Intuicyjnie nasuwa się pomysł, aby użyć średniej arytmetycznej. Niestety nie jest to dobry pomysł. Wynika to z faktu, że chcielibyśmy porównać wartości różnych mianownikach.
Precision = \frac{TP}{TP + FP}Recall = \frac{TP}{TP + FN}Inny przykład z życia wzięty pomoże nam przedstawić, dlaczego nie należy tak robić.
Jeśli jedziesz rowerem pierwszą godzinę 10 km/h a kolejną 20 km/h, po dwóch godzinach przejedziesz 30 km, co da średnią 15 km/h. Wszystko się zgadza, bo mianowniki są te same.
Jeśli jednak pierwsze 15 km pojedziesz 10 km/h a drugiej 15 km pojedziesz 20 km/h, to ile wyniesie średnia prędkość?
- Przejechanie pierwszych 15 km z prędkością 10 km/h zajmie 1,5 h.
- Przejechanie kolejnych 15 km z prędkością 20 km/h zajmie 0,75 h.
- Łączny czas podróży = 2,25 h.
- Średnia prędkość = 30 km / 2,25 h = 13,33 km/h.
Aby uśrednić te dwie wartości, muszą być wyrażone w tej samej jednostce. Dla wyliczenia średniej prędkości posłużyliśmy się tak naprawdę średnią harmoniczną.
To samo możemy zrobić porównując Precision i Recall, które mają różne mianowniki. Użyć średniej harmonicznej. Nosi ona nazwę F1.
F1 = 2 * \frac{Precision * Recall}{Precision + Recall}
Metryka F1 wyniesie zero dla sytuacji gdzie Precision=1 i Recall=0 – co dobrze oddaje, że model jest bezużyteczny. Średnia arytmetyczna w tym wypadku byłaby równa 0,5.
Interpretacja i zastosowanie
Pomyłki FP i FN są równie ważne.
Precision uwzględnia fałszywie pozytywne a Recall fałszywie negatywne.
Nie ma znaczenia czy Orecision=0,5 Recall=0,7 czy na odwrót wynik będzie taki sam.
Liczba pomyłek jest obliczana względem fałszywie pozytywnych
To bardzo ważny punkt dla niezbalansowanych zbiorów danych (tam, gdzie etykiet jednej klasy jest kilkukrotnie więcej niż drugiej). Ten punkt stanowi jednocześnie krytykę dla F1, ponieważ nie uwzględnia prawdziwie negatywnych. Alternatywą jest użycie Matthews correlation coefficient, która właśnie uwzględnia wszystkie komórki tablicy pomyłek dla klasyfikacji binarnej.
Podsumowanie
Tablica pomyłek to punkt wyjściowy do oceny model klasyfikacyjnych. W praktyce chcemy jednak porównywać wiele modeli ze sobą zatem potrzebujemy skondensowanej formy przedstawienia skuteczności modelu niż macierz 2×2 lub większe. Na pomoc przychodzą metryki wyliczane na jej podstawie.
Przykładowe metryki to Precision i Recall i Specificity. Nie można jednak ich interpretować w oderwaniu od siebie a tym bardziej polegać tylko na jednej z nich. Chcąc wyrazić jakość modelu klasyfikacyjnego jedną wartością możemy się posłużyć metryką F1, nie należy jednak zapominać, że i ona ma swoje wady.
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Źródła
- http://mlwiki.org/index.php/Precision_and_Recall#Precision
- https://en.wikipedia.org/wiki/F-score
- https://en.wikipedia.org/wiki/Precision_and_recall
- https://www.youtube.com/watch?v=Kdsp6soqA7o&ab_channel=StatQuestwithJoshStarmer
- https://www.youtube.com/watch?v=vP06aMoz4v8&ab_channel=StatQuestwithJoshStarmer
Inne artykuły


