
W replikacji leader-follower i leader-leader to klient wysyła dane do jednego z węzłów, a następnie synchronizacja odbywa się w osobnym procesie – cały ciężar gatunkowy na barkach bazy danych. Czy ten tok może odbywać się inaczej? Tak, w dodatku jest to bardzo popularne rozwiązanie.
W alternatywnej metodzie to klient wysyła żądanie zapisu do wielu replik. Możemy również wprowadzić do gry kolejnego aktora, który będzie wysyłał żądania zapisu w imieniu klienta. Nazywamy go koordynatorem.
Ten styl replikacji nosi miano Dynamo, oczywiście od prekursora tego ruchu DynamoDB. Jest to baza z modelem danych klucz-wartość, o którym więcej pisałem tutaj.
Co jednak w sytuacji, kiedy jedna z replik nie działała w trakcie danego zapisu, a następnie to z niej chcemy wyciągnąć dane, które rzekomo zostały zapisane? Podobnie jak podczas zapisu, w odczycie bierze udział więcej niż jeden węzeł i odbywa się demokratyczne głosowanie – wygrywa większość. Klient otrzyma wpis, który miał najwięcej głosów. Jeśli któryś z węzłów miał inne zdanie podczas odczytu, zostanie on zaktualizowany do właśnie ustalonego konsensu.
Podczas głosowania nie porównujemy danych, a dodatkową metadaną – wersję danych.

Co więcej, dla zapisu najpierw robimy odczyt, aby sprawdzić obecny numer wersji. Następnie, podczas wkładania danych do bazy, sprawdzamy, czy w tym czasie nie uległa ona zmianie. To dodatkowe zabezpieczenie, które broni przed nadpisywaniem.
To ile tych replik bierze udział w zapisie i odczycie?
Jak się już pewnie domyślasz, jeśli podczas odczytu będziemy czekać na mandat wyborczy od każdej repliki, to czas odczytu bardzo się wydłuży – będzie po prostu tak wolny, jak najwolniejsza replika. Ile zatem replik powinno brać udział w odczycie, a od ilu należy czekać na potwierdzenie podczas zapisu?
Bezpieczne rozwiązanie zakłada, aby choć jedna replika była „na zakładkę”. Załóżmy, że mamy 5 replik. Jeśli podczas zapisu będziemy czekać na potwierdzenie od 3, a podczas odczytu również od 3, to zawsze skorzystamy z tej, która przyjęła odczyt.

Równanie, które opisuje tę zasadę:
r + w > n
r – liczba replik, z których robimy odczyty. Od słowa read
w – liczba replik, do których robimy zapis. Od słowa write
n – liczba wszystkich replik
Techniczny termin opisujący tę sytuację, który możesz spotkać w literaturze, to kworum (quorum); pochodzi z łaciny. Oznacza minimalną liczbę członków zgromadzenia niezbędną do podjęcia ważnej decyzji.
Zmienne r i w są oczywiście konfigurowalne i zależą od wymagań. Jeśli twoja aplikacja ma charakter ready-heavy, to r będzie znacznie mniejsze niż w.
Możemy oczywiście złamać tę zasadę i w + r < n. Kosztem spójności danych zyskamy na czasie odpowiedzi.
Niestety nawet r + w > n nie zapewnia, że zwrócimy aktualne dane, bowiem w replikacji leaderless nikt nie odpowiada za kolejność zapisu danych i podczas współbieżnych zapisów dochodzi do konfliktów.
Wyobraźmy sobie następującą sytuację. Dwóch klientów (A i B) w tym samym czasie wysyła do 3 replik informacje o nadaniu różnych wartości dla klucza X. W związku z tym, że konfiguracja bazy to w = r = 2, oba zapisy skończyły się powodzeniem, mimo że:
- węzeł 1 otrzymuje zapis od A, ale nigdy nie otrzymuje zapisu od B z powodu przejściowej awarii,
- węzeł 2 najpierw otrzymuje zapis od A, a następnie zapis od B,
- węzeł 3 najpierw otrzymuje zapis od B, a następnie zapis od A.
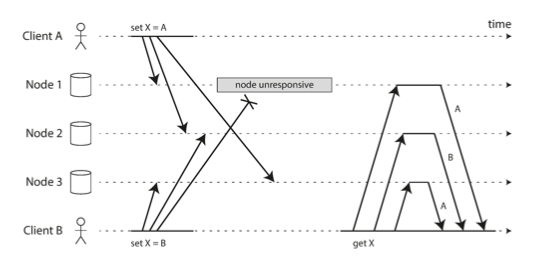
Ta sytuacja sprawiła, że mamy konflikt. Węzeł 2 uważa, że ostateczna wartość X to B, podczas gdy inne węzły uważają, że wartość to A.
Jest to niedopuszczalne i trzeba coś z tym zrobić. Koniec końców repliki muszą mieć taki sam stan. Na szczęście istnieje kilka strategii, bo problem ten jest i powszechny i ważny. W większości nie wymagają ingerencji developerskiej, całą odpowiedzialność bierze na siebie baza danych.
Źródła
- Designing Data Intensive Applications – M. Kleppmann
- Replikacja danych – Wikipedia
- Definicja kworum – Wikipedia
Udostępnij ten wpis
Dobrnąłeś do końca. Jeśli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły



2 thoughts on “Replikacja Leaderless [Replikacja 4/5]”
Comments are closed.